Go Map Source Code Review

1. Intro
Map is an important data structure in Go. As a programmer, I use it in programming tasks everyday. However, I have very little knowledge on the implementation detail of map which may cause dagerous and unexpected bugs. In this article, I want to deeply look inside the source code and understand the implemntation of Map.
source code: src/runtime/map.go
2. Data Structure
First, take look at the data structure.
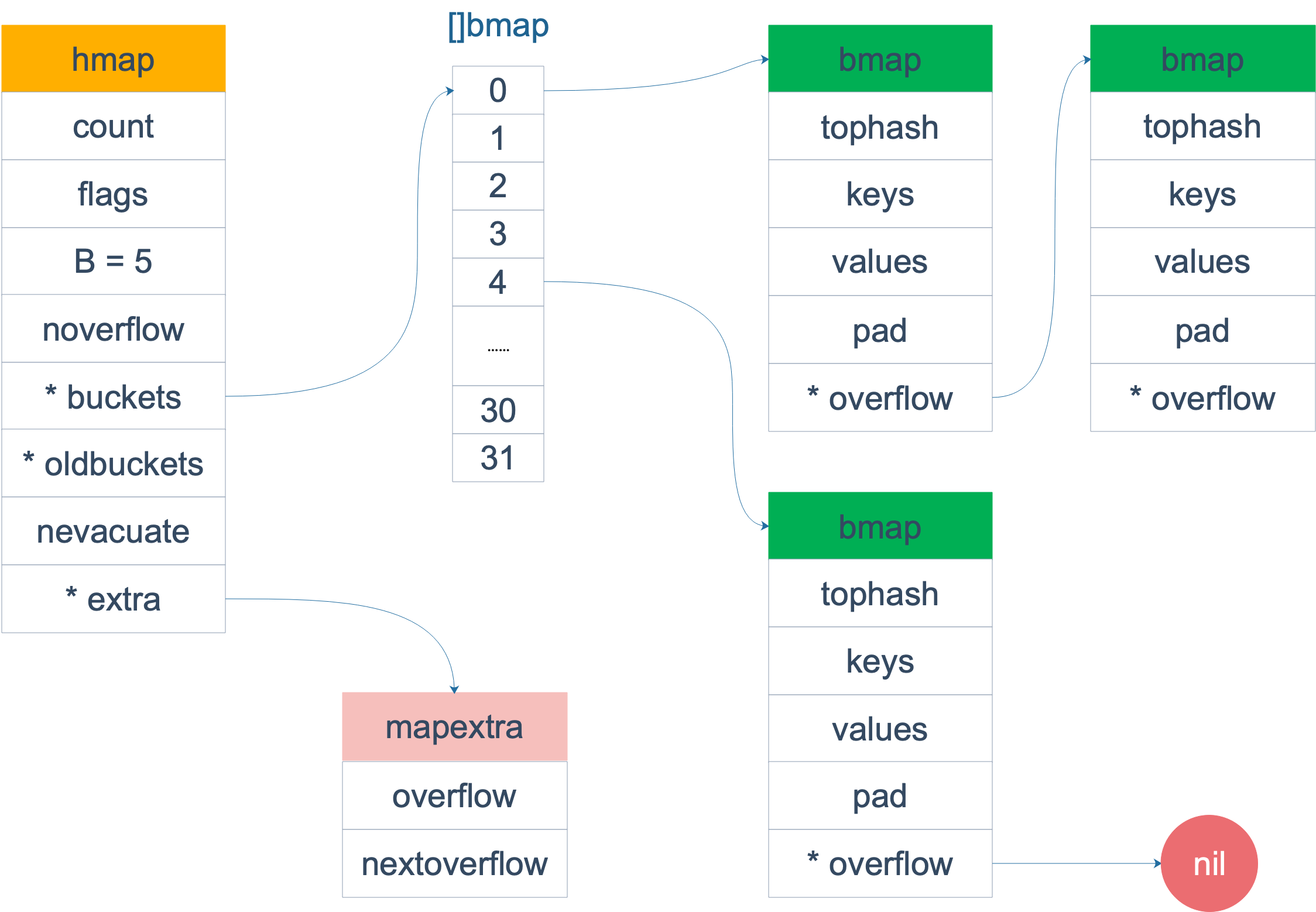
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
| Name | Definition |
|---|---|
| count | is to indicate the size of the map(used by len() builtin) |
| flags | represents map status |
| B | a map has 2^B buckets |
| noverflow | number of overflow buckets |
| hash0 | a hash seed, a random number |
| buckets | points to array of 2^B Buckets. may be nil if count==0 |
| oldbuckets | points to the old buckets. If it points to nil, the map is not growing |
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// ...
)
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
bmap is the bucket for Go map, it can store 8 pairs of k-v by default. It stores the actual key/value data in map.
The actual key/value and overflow is added in the compile time.
A visualisation of Go map is as belows.
3. Operations
Map in Go is a implementation of a hashmap. There are 5 main operations, including creation, get, assign, deletion and growth. Let’s go through the implementation and detail one by one
Creation
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
The map creation is quite straight forward. A random number for hash0 and caculate a appropriate size for B and create the buckets. The bucket size B is caculated by a overload factor which we will discuss later.
Get
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
In the access function, First it checks the flag status to see if there is any goroutine writing to the map. If there is any go routine writing to the map, a panic occurs. This means map in Go is not thread-safe. Next, it get the hash value(uint64) from the key, noted that different maptype has its own hash and equal methods. It will use the hash value to to further find the actual location of the key in the map.
In the implementation we can see that the last B bits is used to find the nth buckets in the bucket list and it will loop over the bucket and see if the key match first 8 bits(generate by tophash(hash)) of the hash value. The finding process is a 2 layers for-loop. It will try to match the hash with in the bucket. If no key is match, it will continue to match key in the bucket in the overflow bucket.
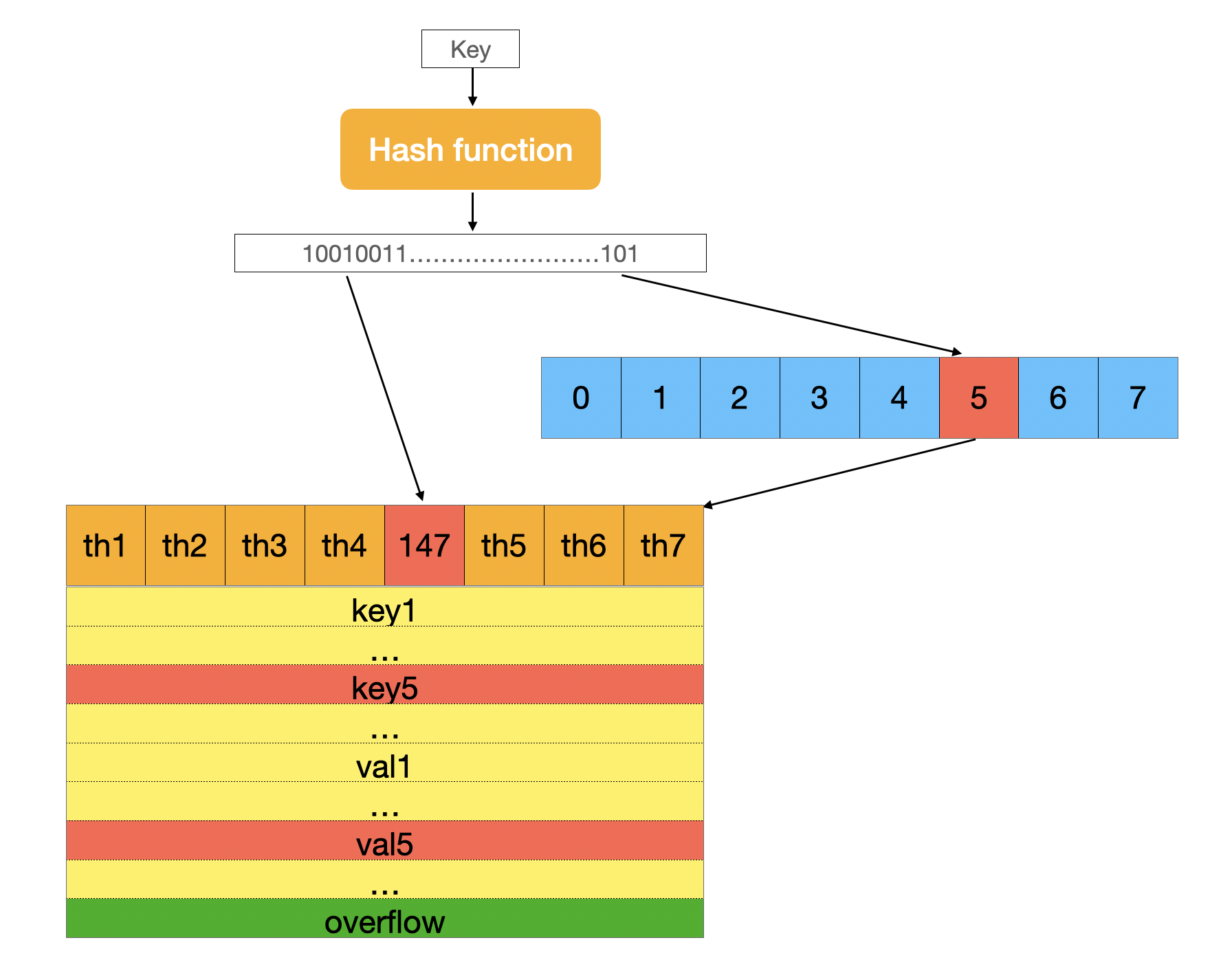
Assign
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// ...
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
In the assign process, first, it checks if the map is empty or there is any goroutine writing to the map. For either cases, a panic occurs. Next, it updates the flag to writing status. There are 2 cases for the assignment - key update or key insertion. A goroutine will try to find the key in the map first and update it, if the key is not found it will do the insert operation. Key update is simple because the map doesn’t increase the size, hence, no map growth is in consideration.
For case of key insertion, a goroutine will do the map growth by checking
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
After the growth is done, it will insert the key/value to the inserti position which is reserver during the for-loop. The writing flag will be switched off in the end.
Delete
The delete process is similar to the get except the writing flag will be switched on during the deletion. The process is simple, get the position and remove the key, value.
Growth
One of the reason to use map is because of its O(1) search and insert complexity. However, when the keys increase in the map, there are more collision which cause the map depraciate to a linked list(O(N)) complexity. Hence, we need a strategy to grow the map and prevent the depreciation. First we need a critiria to trigger the growth. Here is the definition.
// trigger the growth
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// threshold 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// too many overflow buckets
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}
There are two type of growth - Same size growth and Get bigger
- Same size growth: If the growth is triggered by too many overflow buckets, it means the size of buckets is enough. The only thing to do is to reassign the k-v to make the map more compact
- Get bigger: If the growth is triggered by over load factor, it means we need more buckets. B will increase by 1 and the number of buckets will be double size.
The implementation is in hashGrow belows.
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
In hashGrow function, it create the newbuckets according to the new B value. The number of buckets may or may not increases(depends on which type of growth). The previous buckets will be assign to the oldbucket and the value will be copy to the new buckets in the future. Noted the buckets k-v data movement is a incremental process, it is not done by once. The copy process is done by growWork() and evacuate()
// in assign and delete operation
if h.growing() {
growWork(t, h, bucket)
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
The growWork is triggered by assign and deletion and will call evacuate twice. It will move at most 2 buckets each time(because a bucket may be moved already).
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
In evacuate, the idea is simple. The steps is as belows
- Find the place of position in new buckets
evacDst. For the Same size growth the destination is always the corresponding bucket. On the other hand, Get bigger will have 2 candidates buckets depends on the first digit of last B hash digit.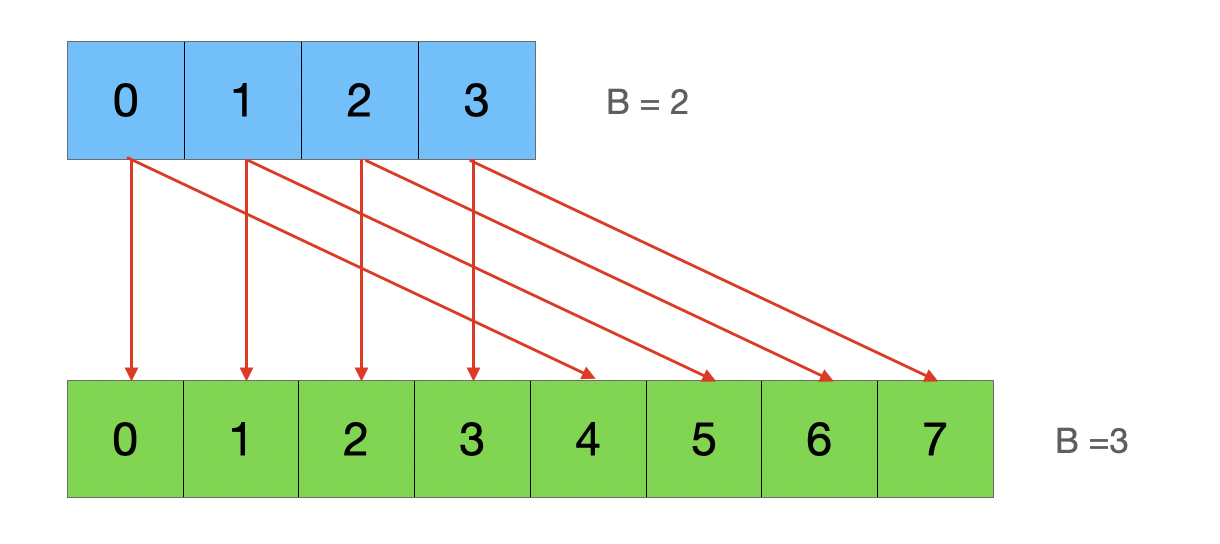
- Loop the old bucket and copy the data to the new buckets.
- Mark the hmap
nevacuate. The growth buckets movement is incremental, the old buckets will be removed once the old buckets data migration is successfully done.
4. Conclusion
Go map is a classical hash map implementation. It deals with a set of common problem in hashmap implementation including the bucket data structure, hash function, growth strategies design etc… After go through the source code, we found the implementation is quite straight forward and easy to understand. We also found that with using the map, we need to always be care of the thread-safe issues. Go map read/write is not thread-safe, prevent multiple go routines write to the same map or use a lock properly.